

 返回
返回文章来源于博物馆头条微信公众号
01
“故事视界”
STORY HORIZON
博物馆的叙事,是根据隐藏在一系列馆藏物品背后的故事(事件)和情节(事件之间的联系),来解释它们之间的联系。故事和情节之间的联系,可以通过实体空间中物品的分类和摆放位置巧妙地传达,或是更为明显地通过书面文字呈现,例如反映在博物馆的藏品目录上。博物馆叙事的其他案例,还包括参观行程、语音导览、教学活动和宣传册页。需要注意的是,这些活动背后的故事基本都是一样的。
博物馆专业人员可以在“故事视界”网站上创作博物馆的叙事。“故事视界”网站可以从一个基本的故事中衍生出多个不同的叙事,使博物馆的专业人员无需每次都根据不同类型的叙事重新创作一遍故事。这有点像“一千零一夜”(1001 stories)和“政文门户”(PoliCultura Portal)这两个网站,都支持从一个基本故事中衍生出多个叙事系统。
“故事视界”网站除了能采集故事里的物品和主题,还能根据不同的独立事件创作故事,并通过情节把所有事件联系在一起。“政文门户”网站为大量的故事增加了各种层面的信息,便于读者浏览;“故事视界”网站则采用相仿的方法,使用不同的属性和数值来描述独立的事件,为浏览故事和实现部分的可视化提供了更多选择。
使用“故事视界”网站,博物馆里不同分工的专业人员可以共享相同的工作资料,还能提出各自的解读。策展本体模型(curate ontology)所建构的故事、情节和叙事模型,同样反映了“故事视界”创作环境的体系架构。
这一观点反映了故事、情节和叙事之间的差异,与查特曼(Chatman)等结构主义者有关叙事的论点是一致的。
由于“故事视界”网站运用的方法旨在采集所有与物品有关且能被讲述的故事,因此在编组和排定博物馆附属内容的过程中,需要依据故事构建和叙事的原则。这就与其他按照元数据(诸如艺术家、时间或地点)的相似性来搜索和排序博物馆内容的方法恰好相反。因此,“故事视界”网站的方法不仅能为用户搜索单件藏品或搜索涵盖多件藏品的展览故事提供帮助,而且还能让观众看到展览背后的故事,并根据自己的兴趣或视角进行二次创作。
02
建立档案卷宗
Build a file
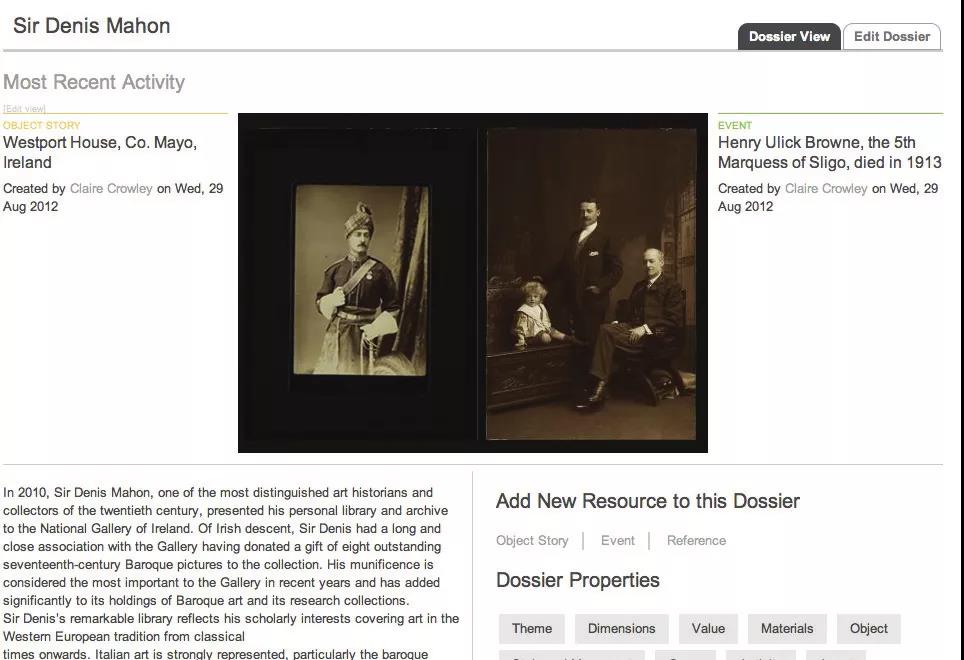
图1 基于艺术史学家丹尼斯·马洪的生活和艺术类收藏的档案卷宗
“故事视界”网站的主要工作空间叫做“档案卷宗”(dossier),作者们可以在这里收集他们想要在故事里讲述的收藏对象。图 1 是基于艺术史学家丹尼斯·马洪(Denis Mahon)的生活和艺术类收藏的档案卷宗,由爱尔兰国家美术馆(National Gallery of Ireland,NGI)上传至“故事空间”网站。
档案卷宗里的每件藏品都有至少一个与之相关、从不同角度讲述的故事。比方说,故事的内容可能与作品的创作时间、创作方式、创作灵感或是表现的寓意有关。图 2 是关于 17 世纪早期艺术家圭尔奇诺(Guercino)的作品《圣海伦娜和她的两个女仆》( Saint Helena withTwo of Her Handmaidens )的故事。可以看出丹尼斯·马洪对圭尔奇诺很感兴趣,并认为这幅画也是艺术家日后创作的灵感来源。其他与画作有关的故事,还有圭尔奇诺在创作时运用的笔墨,或是圣海伦娜的生平故事。
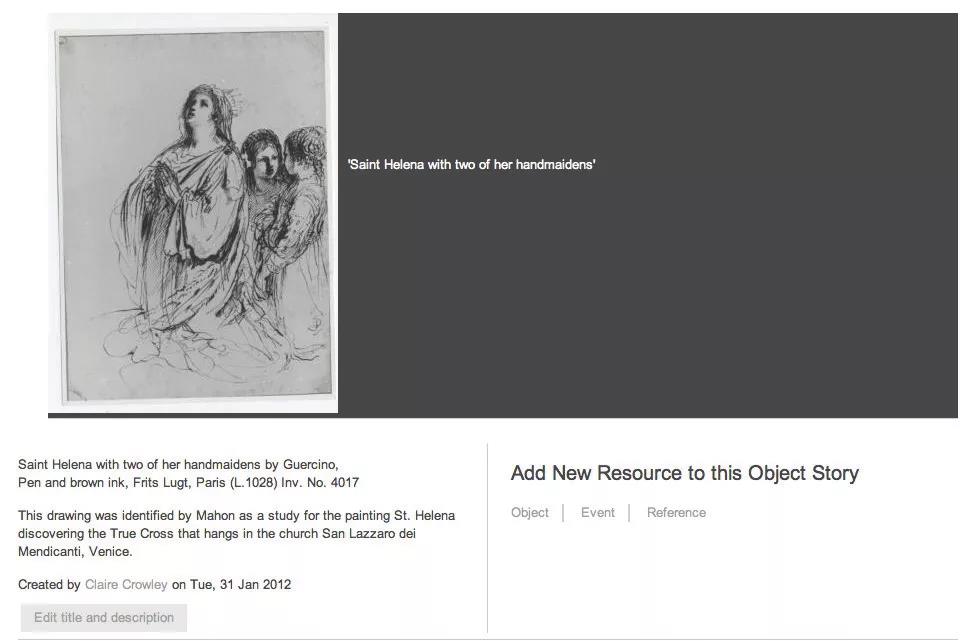
图2 关于圭尔奇诺的作品《圣海伦娜和她的两个女仆》的故事
故事建立在这些关系之上,贯穿多件藏品,伴随着情节逐渐成形。一个情节由多个情节元素构成,而每个元素都明确了事件之间的关系——要么一组事件之间互为联系,要么一个或多个事件影响了另一个或另外多个事件。以图 3 为例,通过一个情节可以看出巴托洛齐的铜版画是如何受到圭尔奇诺作品的影响,或是这两幅铜版画是如何通过相同的媒介甚至相同的艺术家来建立起联系的。
情节是主观性的——因为不同作者对于事件之间的关系,可能会有不同的理解方式。作品《四个女人和一个孩子》( Four Women with a Child )的故事文本中有这样一个情节:“马洪和特纳(Turner)在《女王陛下温莎城堡(Windsor Castle)的圭尔奇诺绘画作品收藏》目录中,尝试性地暗示了两个《圣经》里的话题——法老女儿和幼年摩西(Moses)的故事,或撒拉(Sarah)赶走夏甲(Hagar)和以实玛利(Ishmael)的故事。”
当确定藏品和情节后,叙事结构决定了最终叙事所呈现的藏品对象顺序。例如,丹尼斯·马洪的叙事构成就可能专注于前述有关圭尔奇诺 / 巴托洛齐的情节,使用图 2 和图 3 所示的 3 幅画作及其故事内容,来说明艺术家之间的联系。

图3 巴托洛齐《刺杀暗嫩》和《四个女人和一个孩子》作品的故事
03
网站提供写作支持的推理引擎
Site provides writing support forreasoning engine
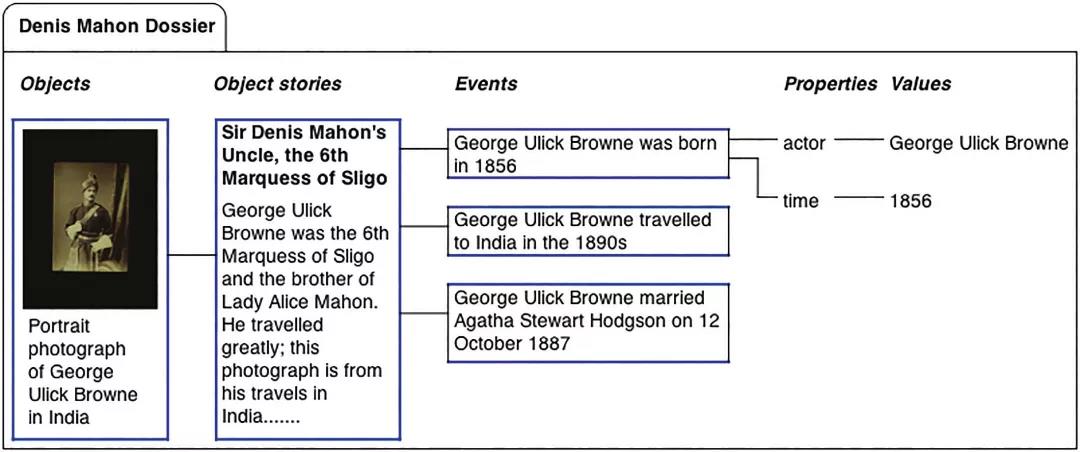
图4 档案卷宗的模型
“故事视界”网站的推理功能在叙事发展的不同阶段为作者提供支持。提供推理支持的主要领域包括:
1. 情节支持(support for plot)
推理可以提供档案卷宗中现有不同事件之间的联系,或根据故事“视界”提供新的事件素材。“视界”包括当前故事的背景(时间和地点)和故事的主题。当识别新出现的主题时,由于在海量信息中进行人工识别的难度很高,因此可以使用推理分析的方式来鉴别上传到档案卷宗中的藏品事件的写作模式。这项功能可用于推动新的故事情节发展。
2. 叙事支持(support for narrative)
推理分析会建议故事情节的组合方式,以产生不同的戏剧效果,使事件中潜在的矛盾冲突情节和主题信息得到最佳利用。最终的叙事是以故事事件、主题和情节为基础的有序内容组合。本体模型使推理分析支持成为可能。本体模型及其支持的其他推理方式,是下文讨论的重点。
04
策展:体现事件、情节和叙事
prepare for the fair
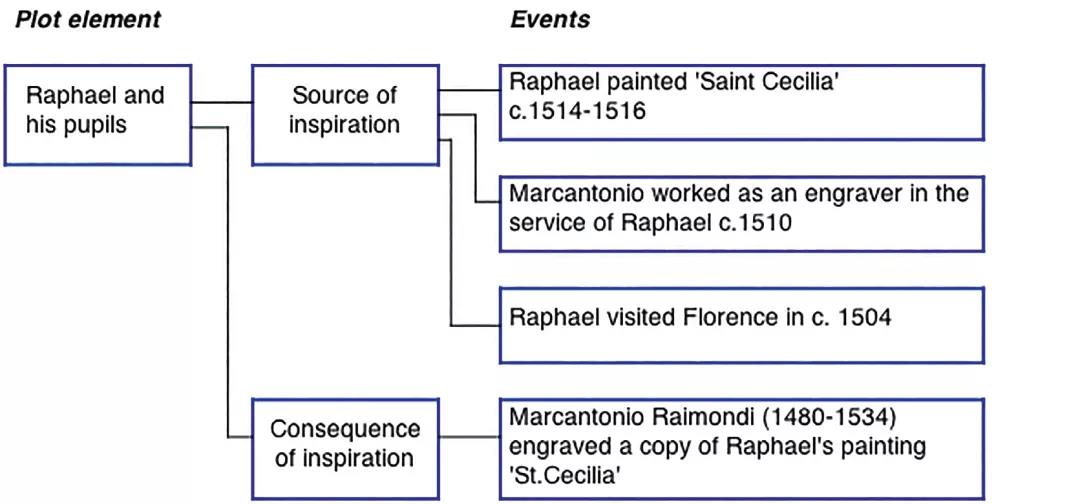
图5 丹尼斯·马洪档案卷宗中的一个情节模型
策展本体模型提供了一种表现博物馆叙事以及背后故事和情节的方式。以下概述了讨论推理分析支持所必需的本体模型。
1. 事件
策展本体模型中有两种故事类型:一种是与某件藏品相关的事件;另一种是与档案卷宗里的好几件藏品都有关的故事。故事由独立的事件组成,清楚明晰地反映在策展中。这使单独的事件可以在不同故事中发挥作用(也可在同一个故事中有多个不同的情节)。策展本体模型中的事件由标题、说明以及一组用于描述事件的属性组成。
除了年代、所有者/代理人、地点、活动和物品等相对标准化的事件属性外,事件还能描述与博物馆有关的诸如尺寸、材料、艺术史时期和所属流派等属性。通过与博物馆合作伙伴的讨论并基于现有的事件架构,共得出12个属性。
作者可以选择手动输入事件,也可以通过“故事视界”网站中藏品的元数据中获取,或是使用外部元数 据 资 源( 如 Freebase 或 FactForge) 创 建。Freebase包含了源于各个资源网站的结构化信息(structuredinformation),特别是著名的维基百科(Wikipedia),为手动搜索或是计算机搜索都提供了极大便利。在Freebase 上存有大量相关艺术家及其作品的信息,以及更为常见的历史人物和事件的资料。FactForge 同样提供了对类似信息的访问,还支持通过计算机对各种可用信息进行推理或关联。未来,从文本中识别的事件(例如作者添加的事件)也可以用于在故事中添加事件。图 4 的概述图,呈现的是档案卷宗中所描述物品、物品故事及其事件和事件属性的本体模型。
2. 情节
故事情节包含了诸多元素,这些元素界定了不同事件的分组,也明确了不同分组之间的关系。最简单的情节元素是相互联系的,这就是一组相关的事件。两组事件之间的关系可以通过“受到影响”“受到激励 ”“做出回应”“受到启发 ”这些词语来进行描述。每一种关系都由“因”(source)、“果”(consequence)成分组成。举例来说,一个受影响的情节元素包含了由一个或多个事件组成的影响原因,以及由一个或多个事件组成的影响结果。
3. 叙事
同样,故事或叙事可以与单件物品相联系,也可以与档案卷宗联系在一起。博物馆的叙事有一个结构,体现了各个元素在叙事中的编组形式。比方说,展览的叙事结构就包括将物品分组、规划并放置在不同的展厅,并且同样的结构能转换成宣传折页里各部分的标题。在策展本体模型中,这种叙事结构表现为一组叙事组件,而每个组件都根据其背后故事和情节特征,被安排在叙事里的特定位置。叙事组件由一个或多个叙事元素构成,每个叙事元素都映射到一个故事元素,这可以是单件物品的叙事、一个事件,或者也可能是参考资料。叙事组件还可以包含子组件,从而创建起叙事的层次结构。
05
通过主题和情境来建构故事
Build a story with theme and context

“故事视界”介绍收藏品的界面
一个故事既有情境(时间和地点)也有主题,而主题是由故事中的事件所反映的。某个故事的主题和情境设定,其数量不一。然而,当一个故事有着多重情境或主题时,通常要进行重新分组,以控制每个特定层级情境或主题的数量。比方说,假若一本书里的事件发生在同一天,那么故事就可以分为早上、中午和晚上这 3 个时间段。随后我们在这 3 个时间段中,再按每一个小时进行细分。如果一本书里的事件横跨了一个世纪,那么故事可以先分为世纪初、世纪中叶、世纪末等 3 个时间段,而各个时段又可以再划分为若干个 10 年,每 10 年还能再进行逐年的细分。这样做的目的是保持连贯性,如果从一开始便提供过多的信息,就会让故事变得难以理解。
利用推理分析的支持,为在“故事视界”上建构故事的作者提供新的事件素材时,便可应用上述原则。档案卷宗中的事件属性值,可用于查找与当前故事的主题和 / 或情境有联系的外部事件,增加建构故事的写作素材。不满足情境或背景要求的事件,不太可能会有关联性。只要稍微调整一下这些新事件的焦点,便可以得到更多相关事件,或是借此强化现有的模式。需要注意的是,故事的发展应当循序渐进,避免时间、空间或主题发生大跳跃。另外,可从大的层级出发(包含所有的故事事件)或是从单独的小层级出发(某个特定的事件分组),在不同层级上丰富故事的内容。
通过聚类事件属性,可以获得情境和主题的信息。由此产生的数值,可用于搜索外部历史数据源,以便为故事提供新的历史背景。举个例子,爱尔兰国家美术馆从丹尼斯·马洪的收藏中选择了一些物品作为测试用的“种子”(seed)内容,从而生成了一个故事。为了获知这个故事的情境,就必须找到故事发生的关键时间点和与之对应的地点,反之亦然(通过地点找到对应的时间点)。这可以通过 k 均值聚类算法( k -means clustering)实现,根据某组对象与聚类中其他对象的相似程度,分成 k 个聚类( k 的值在聚类前已设定)。每个聚类都有一个质心(centroid),决定了该聚类的重要特征,每个对象都要与质心进行比对,确认有足够相似度的对象才能加入这个聚类。在本文的案例中, k 均值聚类算法首先会根据故事发生的时间进行聚类,随后利用每个聚类的质心,得出一组在故事中的重要时间段。针对丹尼斯﹒马洪的收藏内容,所得出的结果是:1934—1934 年、1956—1956 年和 1550—1569 年。
接下来,利用这些时间值对事件进行筛选,将余下的事件属性通过 k 均值聚类在每组事件中反复配对。可以在时间值的基础上加上地点质心进行情境设定,余留的质心值就是主题。第一步聚焦情境,在丹尼斯﹒马洪的档案卷宗中得出以下数据:
· 情境 1:1934—1934 年,伦敦;
· 情境 2:1956—1956 年,博洛尼亚;
· 情境 3:1550—1569 年,罗马。
同样的过程也可以反过来执行,首先以地点作为出发点,可得到以下数据:
· 情境 4:1934—1934 年,伦敦;
· 情境 5:1642—1642 年,博洛尼亚;
· 情境 6:1665—1665 年,罗马。
上述两步过程的目的,并不只是为了一次性聚类所有的值,而是要避免得出原来故事中并不存在的情境(例如伦敦 1642 年)。在上述示例中, k 的值是 3,因此在故事的任一层级上最多可能得出 6 种不同的情境。正如前文所提到的,此举旨避免在给定的条件下出现过多信息量,当按照情节元素进行事件分组时,故事的子区域采用同样步骤,可能会出现其他子主题和子情境。
利用时间和地点这两个值,情境可用于搜索与某个故事相关的事件,而主题则可用于根据与故事的匹配程度来对事件进行排序。在聚类的每一个步骤中,都会推导出与主题相关的属性值质心,将这些质心进行组合,便可得出一组故事中级别突出的属性值。即便主题并不会在故事的每个部分都表现明显,尤其是在故事建构的过程中甚至尚未出现完整的事件,但由于主题终究会贯穿全文,因此有关主题的信息也会不断积累。丹尼斯﹒马洪的档案卷宗中累计的主题信息有:
· 丹尼斯﹒马洪;
· 写作;
· 绘画;
· 阿尼巴尔·卡拉齐(Annibale Caracci);
· 保拉·德拉·佩尔戈拉(Paola della Pergola);
· 瓦萨里(Vasari);
· 批评;
· 艺术家生平;
· 出生;
· 成功。
网上确实有一些可供机器阅读的历史事件资源,可以自行搜索并上传到“故事视界”。这些资源来自维基百科上的文本或时间线,已经按照事件的形式提供了历史信息,是用于丰富故事的理想素材。然而从目前反馈的结果来看,这些资料对于确定情境来说,数量还过于稀少。
我们转而采用 FactForge 链接的开放数据资源库来识别情境的关联数据。正如前文所述,FactForge 提供了从维基百科等来源获取信息的方式,可以通过机器搜索和推理。通过资源描述框架 (resource descriptionframework,RDF)来获取数据,RDF 格式以三元组的形式描述信息,包括一个主语、一个谓语和一个宾语。比方说,通过“主语:人物 A;谓语:出生于;宾语:地点B”这样一个三元组,关联人物A和他们的出生地点B。可以建立检索系统来查找数据,举个简单的例子就是查询所有出生于地点 B 的人。由于反馈的结果不以事件形式出现,因此必须转换这些信息以符合事件的结构,才能包含在故事当中。例如,当检索到一本在某个特定时间段出版的书,则可以写作“某个时间出版了这本书”,表示这一关于出版的事件。
因此,通过查询 FactForge 所创建的反馈数据,能够用来构建历史事件。精心设计的查询体系用于查找在某一时间段发生的与博物馆领域有关的信息,并且信息与根据主题聚类(写作、绘画、 生日)的那些结果相一致。查询结果根据上一步找到的主题信息进行排序。其他主题(例如:丹尼斯﹒马洪和阿尼巴尔·卡拉齐等艺术品的所有者或代理人)可作为参照,从所有反馈的查询结果中挑选相关内容。需要查找的信息包括:
· 某一时期的出生事件,并附上地点链接;
· 某一时期的死亡事件,并附上地点链接;
· 某一时期创作的艺术品,创作者与上述地点有关;
· 某一时期获得的艺术品,艺术品或所有者与上述
地点有关;
· 某一时期的出版物(包括再版),附上地点链接,指向作者与艺术品的链接。
查询系统可以进行调整以适用于其他领域,也能通过改变与某个地点的直接关联程度,从而调节限制性的强弱。任一情况下,在故事中添加某个事件都是可行的,比如出生和去世的事件,创作和购买艺术品的事件,或是发表作品的事件。在丹尼斯﹒马洪档案卷宗的案例中,将时间和地点设定为“伦敦 1934 年”,FactForge 反馈的结果是:
· 唐·贝查迪(Don Bachardy)出生;
· 约翰·科里尔(John Collier)去世;
· 埃舍尔(Escher)创作《静物与球面镜》( Still Life with a Spherical Mirror );
· 菲利普艺术收藏馆(Phillips Collection)于 1934年购买了乔治·布拉克(Georges Braque)创作的《圆桌》( The Round Table );
· 狄兰·托马斯(Dylan Thomas)出版了《诗十八首》(18 poems )。
在这组案例中,事件 1、3、5 将优先排序,因其与前一步中设定的出生、绘画和写作的主题相关。
06
情节关系
The plot relationship

图6 添加新的事件素材,使用外部资源来扩大和缩小故事
我们也可以使用查询系统在外部数据中进行检索,寻找故事中相关人物之间的情节关系。例如,Freebase里有关于影响作用和同侪人际关系的信息。以丹尼斯﹒马洪的档案卷宗为例,通过 Freebase 可以发现——吉安·彼得罗·贝洛里(Gian Pietro Bellori)与尼古拉斯·普桑(Nicolas Poussin)是同辈人。
贝洛里和普桑是马洪故事里的相关人物。“故事视界”的实体有可能在输入时就映射到 Freebase 里的身份标识(ID)上,这便于利用 Freebase 来查找故事人物之间的关系。同样的过程也可用来查找上一步提到的人物。比如在搜索主题和情境时,如果通过 Freebase 发现其与提到的另一名所有者或代理人,并且(或者)与故事中的某个人物存在着联系,那么这名新的所有人或代理者将被认作是艺术家,他的出生、去世、创作艺术品或是售出艺术品的经历,也可能与故事有了更紧密的联系。这则信息可以用于对反馈结果进行优先级的排序。
基于对相似事件的聚类, k 均值聚类算法也可以利用事件属性的数据提出关联的情节元素。在本案例中,k 的值是在与博物馆讨论后得出的最佳分组规模,并且根据可访问内容对各种聚类输出的反馈所得,这表明关联情节元素的分组应当包含 2~10 个事件。在尝试推进情节发展的过程中,规模越小的情节元素越容易加以阐释。因此,这个故事被划分为平均包含约 6 个事件的分组。
一旦建立了情节分组,就有可能在关联的情节元素内,甚至在跨越多个情节元素的事件之间,寻找到更为具体的情节关系。针对可能具有联系性的事件进行总体概述,并以此为指导,逐步专业化地处理情节之间的关系,这种方法与博物馆合作伙伴所建议的工作方式是一致的。上述所有的推理过程都可应用于故事的子部分(如情节元素)或是拓展的故事。图 6 中的图表说明了故事展开的过程。
在图 6 中,A 表示初始的一组故事事件,B 表示故事范围扩大。阴影区域的事件与原始故事的核心相近。C 则表示寻找实体关系。比方说,A 影响了 B,而 A 与C 又处于同侪人际关系。所有者或代理人可以出现在原始故事中,也可以出现在后来发展的故事中。D 表示故事范围缩小——找出相关的情节元素,并在这个范围更小的故事范围内重复进行情节推理;或是再次扩大故事的范围,包括在上一步骤中增加的事件。
这些推理过程可以通过自动为档案卷宗添加与故事相关的事件数据,为作者提供支持,并立即显示在时间轴或地图上。他们也可能会提供一些原先没有考虑到的、可用于补充历史背景的事件。诸如 Freebase 和 Factforge之类的外部信息资源,涉及戏剧、图书、体育赛事、军事事件等内容。非专业的博物馆观众在使用“故事视界”时可能会发现,这些推理过程在帮助他们将故事引到更符合他们个人兴趣的方向。
07
构建叙事成果
Building Narrative Outcomes
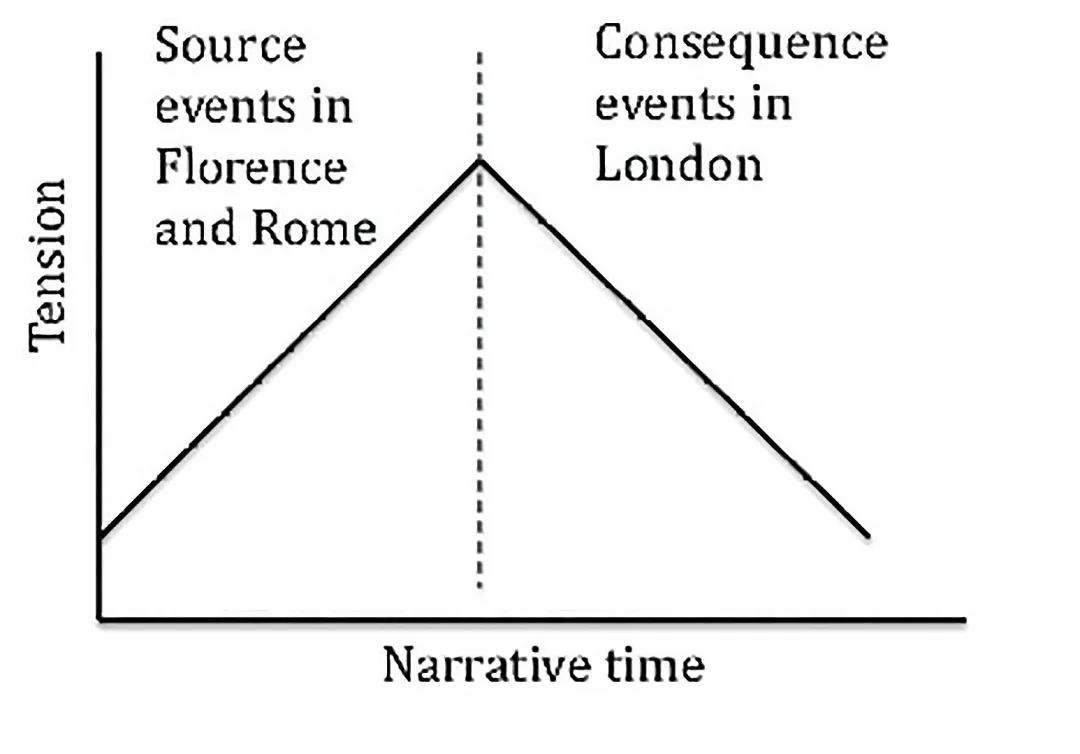
图7 加强叙事的张力
完成故事后,可以通过叙事的形式输出。叙事结构决定了将情节和主题等故事信息呈现给观众的方式,以及物品对象在叙事呈现中的顺序位置。为叙述提供的推理分析支持,可以帮助作者建立起叙事结构,以获得与众不同的戏剧化的效果,并处理主题“相关”情节与其他类型情节信息之间的冲突。由于作者可以任意决定在故事情节中情节元素的数量,因此会产生这些问题,可能出现同一事件被多个情节元素所采纳的情况。
虽然在网络空间中可以使用超链接,或者让某个事件(链接的某个对象)多次出现,但在大多数情况下,都需要按照叙事的顺序,并且一件物品只能出现一次。叙事推理提出了应当使用哪些原则来对故事中的事件进行分组,以及如何在这个体系中编组事件。由于某些事件源于各个物品对象的故事,因此反过来又可以对叙事中物品的编组方式提出建议。
叙事推理提出了基于情节的首要编组原则,即在选定的一组情节元素中对事件进行分类,这是事件的初始分组。可以找到次要编组原则来强调这一点,提出情节元素彼此之间应该如何排序,其内部应该如何组织安排。比如说可将情节元素和事件组织起来,使之更多是按照时间进行排序。另外,也可以通过地点或事件中发生的活动类型等其他事件属性,与情节元素进行比对校正。次要的编组原则巩固了最初的编组原则,并且可以在叙事组织中得到体现。例如配合主题分组对象和关联事件添加时间轴或地图。这个过程可以在叙事的子组件上递归重复。
08
营造戏剧效果和加强张力
Create Drama and heighten tension
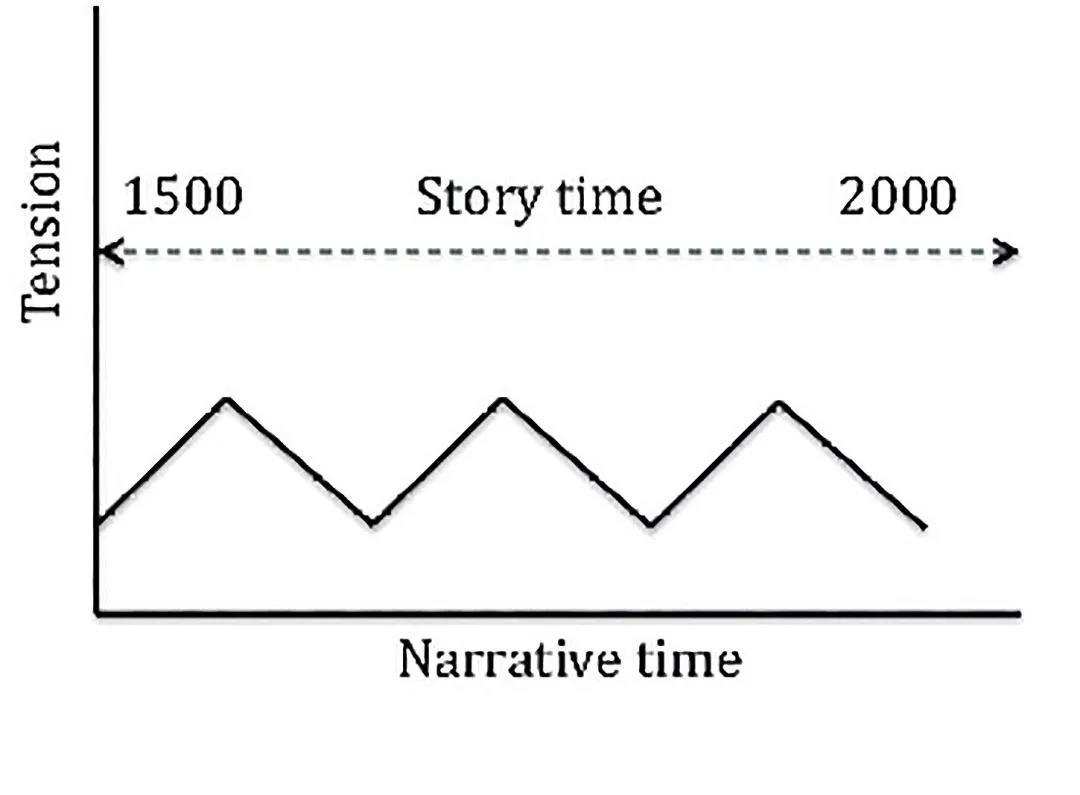
图8 消除叙事的张力
两个部分组成的相关情节(诸如影响、动机、反应、启发等),都有一个“因”和一个“果”。组织叙事一种方法,是先列出所有与原因有关的事件(以及联系对象),然后是所有与结果相关的事件。次要编组原则可以选择运用统计分析方法寻找到最佳的互补原则,以决定“因”事件组和“果”事件组中的分组、排序和物品对象(例如按照时间顺序编组 , 或发现的所有“因”事件都发生在佛罗伦萨和罗马,所有的“果”事件都发生在伦敦)。这样的叙事编组,通过在解决疑惑前引入许多情节元素以增强紧张感,让人更想知道“发生了什么”。图 7 是这种叙述编组原则的示意。请注意图 7 中的时间是指叙事时间,即在观看叙事过程时事件和物品对象相遇的时间跨度。叙事呈现的故事时间,也就是故事事件的发生时间,可能是线性发展的,也可能不是。
1. 消除张力
反之,如果每个情节元素都是在下一个情节开始时就已结束,便不会产生什么张力(图8)。在这个案例中,次要编组原则是故事时间。
2. 加强 / 削弱张力
根据情节来编组叙事的第三种方法,是随着时间的发展,通过选择不同类型的情节元素来加强或是削弱张力。这是基于情节关系的层级结构,赋予了动机“低戏剧”(low drama)的值,并影响“高戏剧”(high drama)的值。
所以说,如果动机性的情节元素先表现出来,随后影响性的情节元素才出现的话,那么张力就会随着时间的推移而加强。在前述案例中,推荐将次要原则作为编组情节的补充;还可以提出不同的情节类型,正像张力最大化的情况:例如通过采用所有的动因,随后是所有的结果,接下来是所有的影响原因和影响结果(图 9,上);
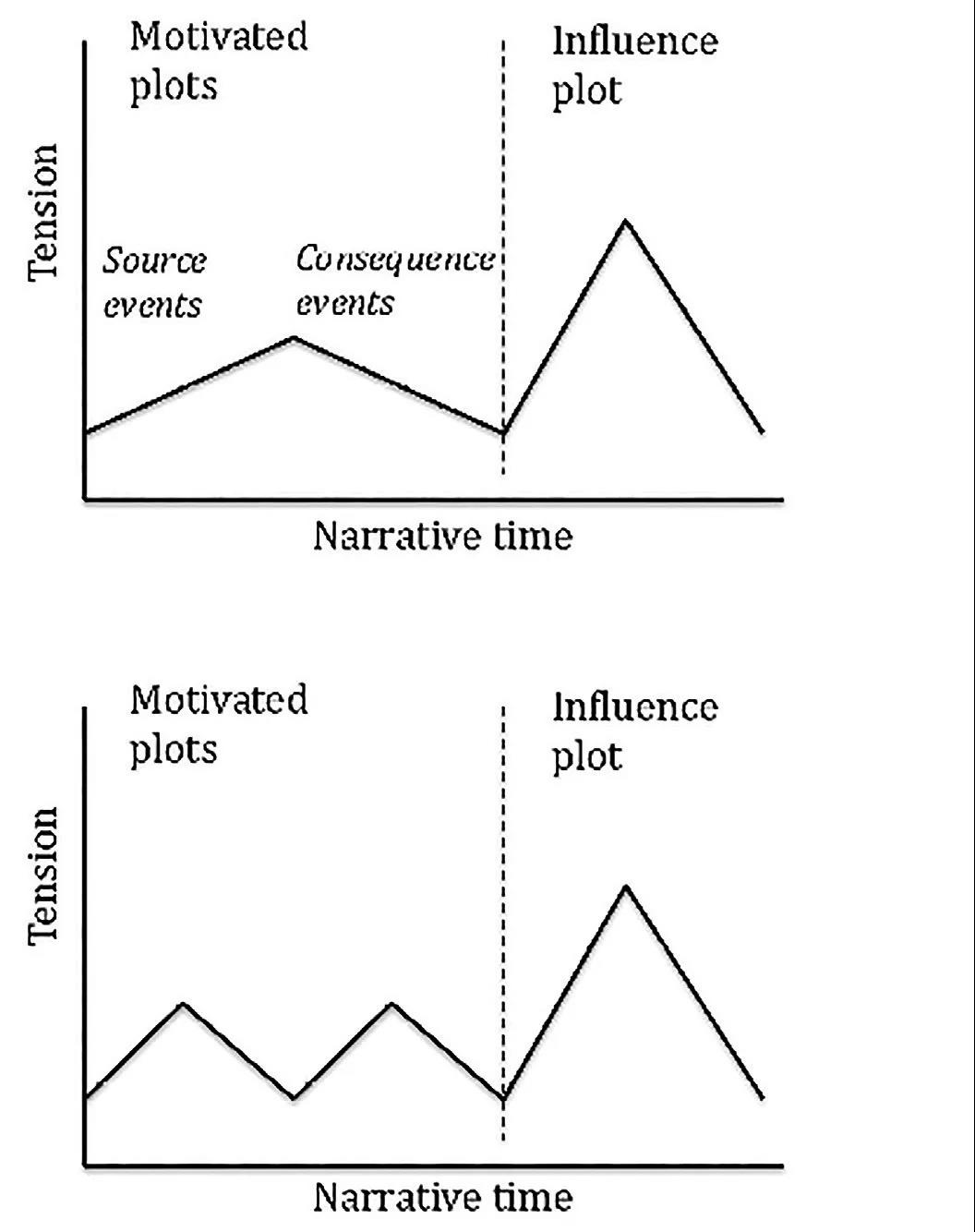
图9 采用不同情节类型制造张力的案例
09
相关/主题编组
Group related topics
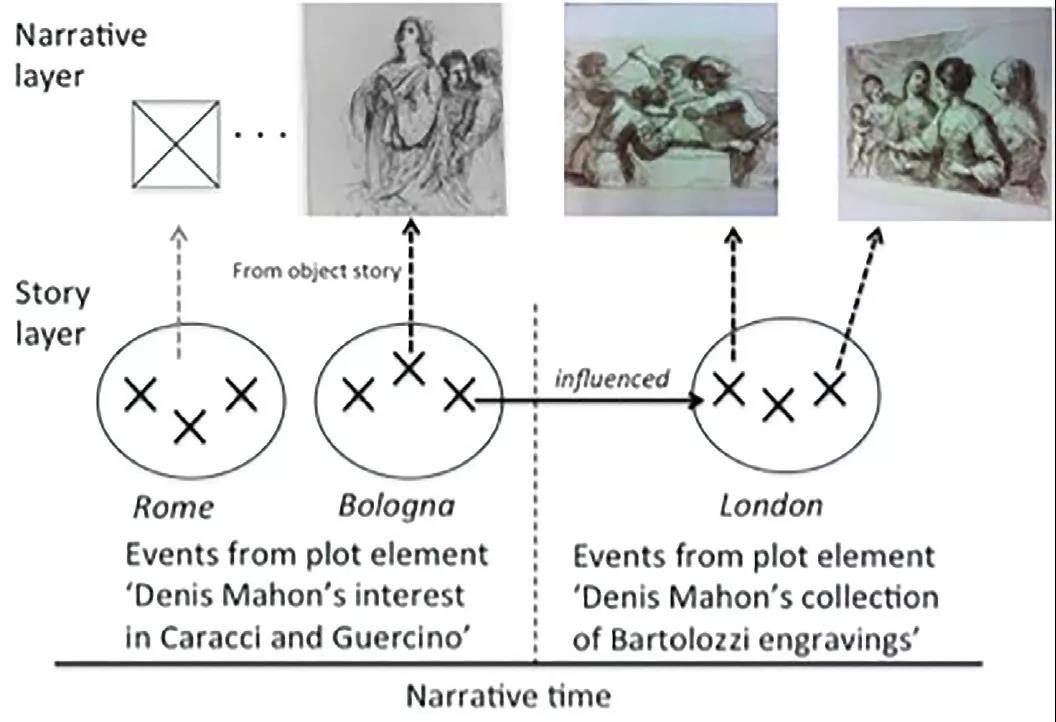
图10 由相关情节组成的叙述故事
相关的情节元素本身就可作为首要的编组原则。同样可以通过统计分析的方法,寻找到最为相符的次要编组原则。一个相关的情节元素可能包含许多次要情节,或是其他更具体的相关情节元素,或是具体说明两组故事影响或动机的两部分的情节元素。若是后一种情况,根据前文提到的原则,另一种叙事结构可能会决定这些从属情节最戏剧化的呈现方式。
10
最终叙事的呈现
Group related topics
最终叙事的形式可以是多种多样的。同样,潜在的故事事件,与物品对象的准确传达程度也会有所不同——例如在没有任何信息与故事相关的情况下,物品虽是独立呈现的,但仍通过潜在的故事原则进行编组 ;而其他情况则是故事和情节被完整书写。无论如何,“故事视界”的关键目标是容许创作能与原始故事和档案资料相关联的故事,即便物理上的联系已不复存在。为了实现这一目标,可以将档案内容与最终叙事一起发布,包括参考资料、未曾使用的对象物品和事件。用户甚至可以创建他们自己的档案版本,可以更改、缩减和扩展已经发布的故事,并形成自己的叙事。终端用户可以得到与原作者相同的推理支持。因此,当选择不同的视角时(例如过滤掉他们当前不感兴趣的对象),故事的主题和情境就会发生变化,从而改变外部所暗示的事件和情节的关系。
11
致谢
expreds one‘s thanks
我们要感谢爱尔兰国家美术馆、爱尔兰现代艺术博物馆(Irish Museum of Modern Art)和都柏林理工学院(Dublin Institute of Technology)所作的贡献。这项工作是“破译”(Decipher)项目的一部分,属于欧盟“第七框架计划”在数字图书馆和数字保存领域的一个项目。
